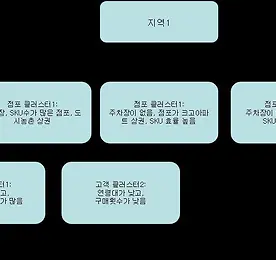
 [점포 클러스터링] #5 클러스터링(K-means method)
클러스터링(K-means clustering) 회귀분석을 통해 매출에 가장 영향력 많이 미치는 변수 3개로 K 평균(K-means method) 클러터링 기법으로 클러터링을 실시한다. K 평균 기법은 R, SAS, SPSS등 데이터 마이닝 통계 패키지를 통해서 실시할 수 있다. 1차 클러스터링 예제 – 점포 정보만 사용 클러스터링 속성 클러스터1 클러스터2 클러스터3 점포크기, 유무, 상권 주차장을 가지고 있으며, SKU수가 많은 점포, 도시농촌 상권 주차장이 없으며, 점포가 크고 아파트 상권, 하지만, SKU 판매 효율은 낮음 주차장이 없으며, 점포가 작고, 도심 역세권, SKU 효율이 높음 위와 같이 3개의 클러스터링을 도출하였다. 위의 결과는 한번에 나오는 것이 아니라, 몇 번에 걸쳐 변수 투입 및..
더보기
[점포 클러스터링] #5 클러스터링(K-means method)
클러스터링(K-means clustering) 회귀분석을 통해 매출에 가장 영향력 많이 미치는 변수 3개로 K 평균(K-means method) 클러터링 기법으로 클러터링을 실시한다. K 평균 기법은 R, SAS, SPSS등 데이터 마이닝 통계 패키지를 통해서 실시할 수 있다. 1차 클러스터링 예제 – 점포 정보만 사용 클러스터링 속성 클러스터1 클러스터2 클러스터3 점포크기, 유무, 상권 주차장을 가지고 있으며, SKU수가 많은 점포, 도시농촌 상권 주차장이 없으며, 점포가 크고 아파트 상권, 하지만, SKU 판매 효율은 낮음 주차장이 없으며, 점포가 작고, 도심 역세권, SKU 효율이 높음 위와 같이 3개의 클러스터링을 도출하였다. 위의 결과는 한번에 나오는 것이 아니라, 몇 번에 걸쳐 변수 투입 및..
더보기
 [점포 클러스터링] #4 변수의 발견과 결정
변수 발견과 결정 점포 클러스터링을 하기 위해서는 클러스터링의 기준이 되는 변수의 선택이 매우 중요하다. 먼저, 변수들을 선택하기 전에 어떤 변수들이 있는 지 확인해 보자. l 점포 변수(store attributes): 행정지역, 상권, 크기, 주차장 유무 l POS 데이터: 매출, SKU수, SKU Type(프리미엄, 가격 민감, PB 등) l 고객정보: 연령, 평균 구매액, 자녀 수, 평균 구매 횟수 등 물론, 이외 클러스터링의 목적에 따라 더 많이 변수가 있을 수 있다. 변수가 정리 되고 나면, 어떤 변수 들이 클러스터링을 하는데 있어서 중요한지 솎아 낼 필요가 있다. 이러한 과정을 변수 프로파일링(attribute profiling)이라고 한다. 예를 들어 총 6개의 매장관련 변수를 가지고 있다..
더보기
[점포 클러스터링] #4 변수의 발견과 결정
변수 발견과 결정 점포 클러스터링을 하기 위해서는 클러스터링의 기준이 되는 변수의 선택이 매우 중요하다. 먼저, 변수들을 선택하기 전에 어떤 변수들이 있는 지 확인해 보자. l 점포 변수(store attributes): 행정지역, 상권, 크기, 주차장 유무 l POS 데이터: 매출, SKU수, SKU Type(프리미엄, 가격 민감, PB 등) l 고객정보: 연령, 평균 구매액, 자녀 수, 평균 구매 횟수 등 물론, 이외 클러스터링의 목적에 따라 더 많이 변수가 있을 수 있다. 변수가 정리 되고 나면, 어떤 변수 들이 클러스터링을 하는데 있어서 중요한지 솎아 낼 필요가 있다. 이러한 과정을 변수 프로파일링(attribute profiling)이라고 한다. 예를 들어 총 6개의 매장관련 변수를 가지고 있다..
더보기
 [점포 클러스터링] #2 클러스터링의 목적은 무엇인가?
클러스터링의 목적은 무엇인가? 이 페이퍼를 읽고 계신분은 어떤 산업에 몸담고 있는지 먼저 명확히 이해 할 필요가 있다. 스킨푸드, 이니스프리, 페이스샵과 같이 화장품 전문점을 산업인지, 롯데마트, 이마트, 홈플러스와 같이 그로서리를 파는 산업인지, 또는 스타벅스, 에인젤인어스, 커피빈과 같이 커피 전문점인지 그밖에도 서점, 약국, 패션&신발을 판매하는 소매점도 마찬가지이다. 산업에 따라 처음부터 점포 클러스터링에 접근해야하는 1차적인 목적은 크게 다를 수 있다. 여기에서는 그러서리를 판매하고 있는 체인슈퍼를 입장에서 소개하고 있음을 염두해 두길 바란다. 그로서리 소매점에서 클러스터링을 할 때는 구색, 스페이스 등과 같은 상품과 진열에 대한 이슈와 가격, 판촉과 같은 가격전략 이슈, 그리고 점포 실적을 비..
더보기
[점포 클러스터링] #2 클러스터링의 목적은 무엇인가?
클러스터링의 목적은 무엇인가? 이 페이퍼를 읽고 계신분은 어떤 산업에 몸담고 있는지 먼저 명확히 이해 할 필요가 있다. 스킨푸드, 이니스프리, 페이스샵과 같이 화장품 전문점을 산업인지, 롯데마트, 이마트, 홈플러스와 같이 그로서리를 파는 산업인지, 또는 스타벅스, 에인젤인어스, 커피빈과 같이 커피 전문점인지 그밖에도 서점, 약국, 패션&신발을 판매하는 소매점도 마찬가지이다. 산업에 따라 처음부터 점포 클러스터링에 접근해야하는 1차적인 목적은 크게 다를 수 있다. 여기에서는 그러서리를 판매하고 있는 체인슈퍼를 입장에서 소개하고 있음을 염두해 두길 바란다. 그로서리 소매점에서 클러스터링을 할 때는 구색, 스페이스 등과 같은 상품과 진열에 대한 이슈와 가격, 판촉과 같은 가격전략 이슈, 그리고 점포 실적을 비..
더보기




